

In 1997, a computer defeated a reigning world chess champion.

Garry Kasparov, considered to be one of the greatest chess players of all time, went up against the tech giant IBM ’s chess computer. Deep Blue was programmed specifically to play chess games, and play them masterfully. And masterfully enough to beat another master. But how did it do it? And how are technologies like AI or machine learning currently leading the charge in the next revolution of industry and innovation?

A crucial component of the supercomputer Deep Blue, and many artificial intelligence or machine learning systems like it, is searching algorithms. Searching algorithms are a section of computer algorithms or instructions that try to find a piece of information from a collection of data. For Deep Blue to determine what move to make, considering the position of its pieces and the opponent ’s pieces on the board, it needs to search over all possible moves. Without searching algorithms, Deep Blue and other AI could not think.
There are many searching algorithms that can be discussed, including the advanced ones Deep Blue and ChatGPT use. We will focus on some simple yet still widely applied ones to at least grasp the concept of searching.
Breadth-first search is a searching algorithm that starts from some point and visits all points it is connected to, then visits the points those ones are connected to, and so on until all points have been visited. Here is a visual representation of how this works with a graph.
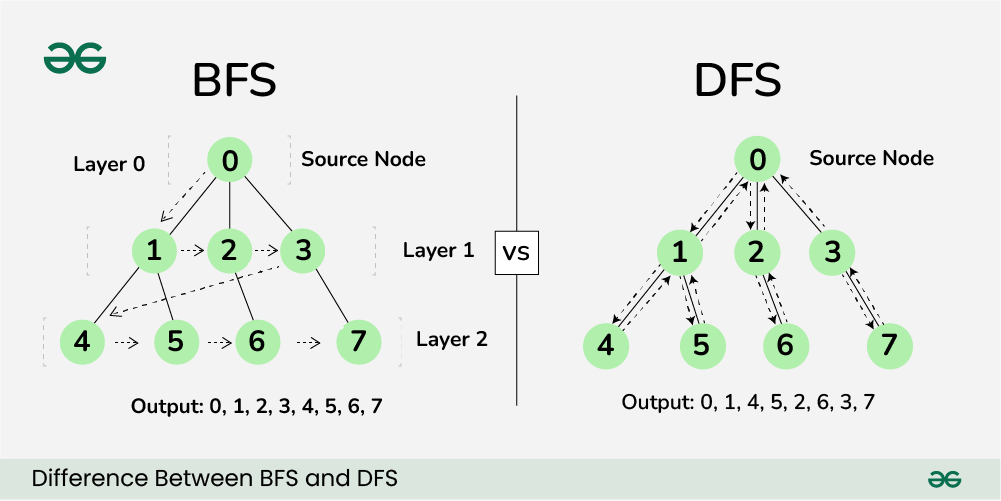
The solid lines show the connections between points in the graph. The source point or node is 0 and is connected to 1, 2, and 3. It then makes sense when visiting points starting from 0 that 1, 2, and 3 are visited next, and shown in the output in the given order. The next layer of points are connected to the previous layer so they are all visited as well.
Another popular searching algorithm is depth-first search. Depth-first search starts from some point and visits the graph branch by branch rather than layer by layer.
A branch here is any path that can be followed from a point or node to another. An example is going from 0 to 1 to 4, wherein 1 is a branch of 0 and 4 is a branch of 1. After that, the branch from 1 to 5 would be visited, then 0 to 2, 2 to 6, and so on.
This concept of searching applies directly to the next topic of interest, a field of AI or machine learning called reinforcement learning.

Tesla has made many headlines with their self-driving cars.
In order for the AI behind the wheel to learn this complex task, it uses the machine learning methodology of reinforcement learning. Reinforcement learning is about a computer learning to perform a task by just making decisions, receiving rewards or punishments for doing so, and logging these results to determine what to do at any given moment to complete it ’s task. It 's very similar to how we learn new things, by just making decisions, receiving feedback on what we just did, and learning what works and what does not. When you learned to drive, you got used to how to accelerate and brake by pressing the pedals with differing amounts of pressure, figuring out how quickly or slowly you would move, and using this feedback to understand how to get the car moving and stopping.
Reinforcement learning would apply to a self-driving car by tasking it with driving from some starting location to a destination, while following the rules of the road. Its decisions would be accelerating, braking, turning, and others, depending on the road being driven on. It would be rewarded for moving in the correct direction or making the correct turn to get closer to the destination. It would be punished for hitting something or making an incorrect turn.
A commonly used computer algorithm or set of instructions that uses reinforcement learning is q-learning. Q-learning gives each decision the computer can make a positive or negative reward, depending on where it is in its environment. It will use searching to run through the environment multiple times and ensure it explores all actions at every space and figure out exactly what to do to complete its task. For a self-driving car, again, it would be rewarded positively for turning correctly or accelerating in the direction of its destination, but be punished for straying from it. The car may even need to drive on the roads multiple times, either physically or in a computer-simulated environment, to understand how to drive and how to get to a destination.

The most talked about AI within the past couple of years has been ChatGPT. It is of little surprise why it has received so much buzz. It is one of the most impressive and useful pieces of software we have seen yet.
From answering your homework questions …

to generating images …
to even writing programs.
To get a sense of how ChatGPT and other text generation AI like it can do these tasks, we look at the most perplexing area of machine learning. Deep learning attempts to mimic how human brains make decisions to power the thought process of computers. Put simply and naively, we process tasks, our environment, etc. by taking inputs like what we see and feel, feed them through the neurons in our brain, and use the outputs to make decisions and fuel our understanding of what we do and observe around us. This is all done subconsciously and done by everyone at different rates.
Computers then have to create and use a simulated brain called a neural network, which feeds information into artificial neurons, organized in collections called layers, and uses their outputs to make decisions.
ChatGPT might do this with a human image we give to it by, for example, inputting it into its first layer and analyzing the color and parts of the body. Based on what it discovers from each neuron ’s output, it determines what neurons to visit in the next layer and gives them inputs to then analyze, say, parts of the hands and the camera. It does this until reaching the last layer, which analyzes more micro aspects like sections of a finger, and gives the final outputs to the output layer. This layer makes the final decision or output as to what it has processed, like communicating what the person in the image is. Below is an illustration of how the neural network looks.

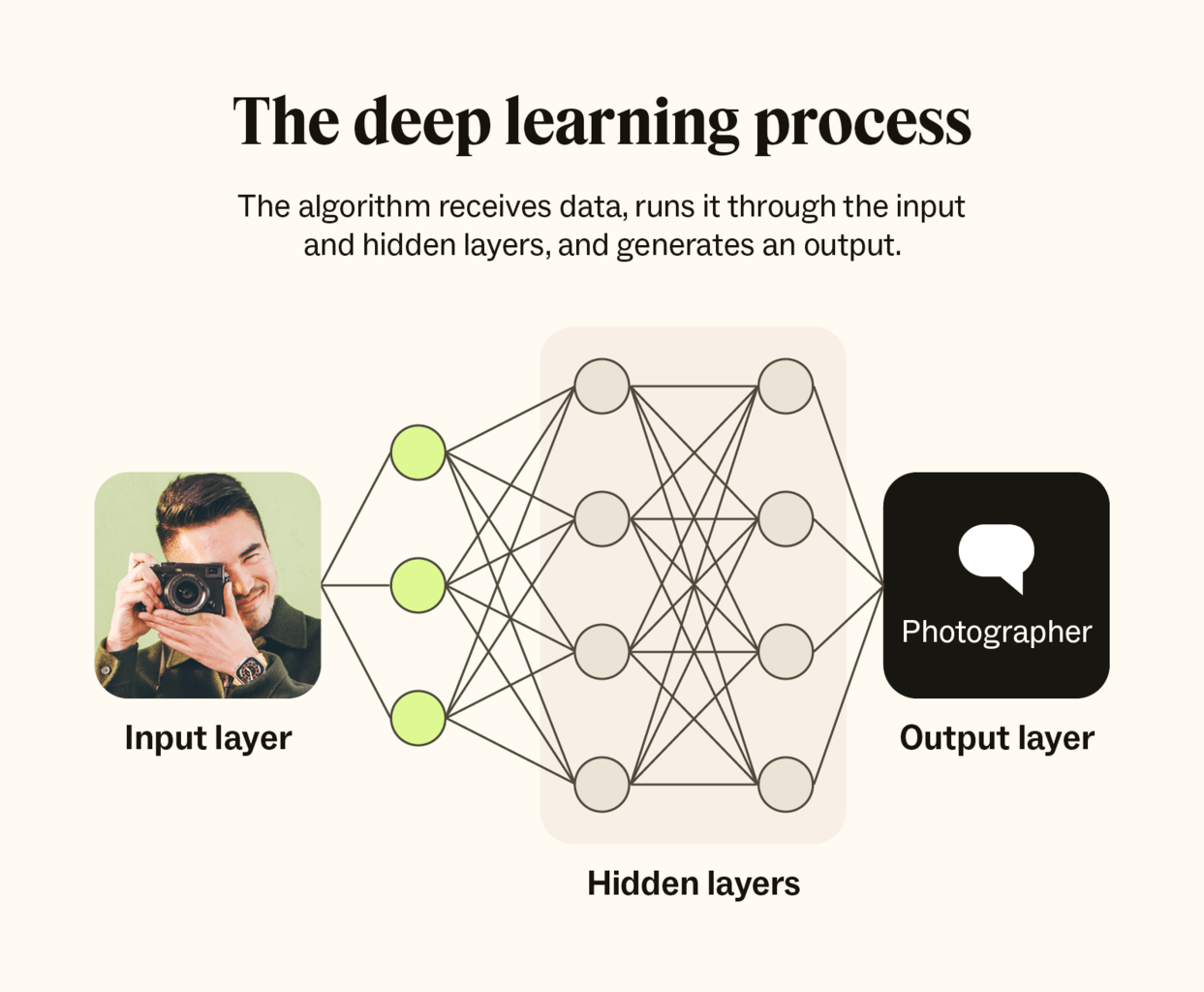

To gain a more intuitive sense of how deep learning works, we will draw and move through our own simple neural network.
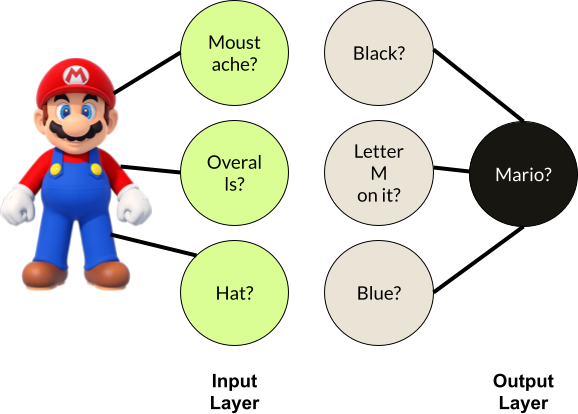
This neural network is for determining whether or not an image is Mario or not.
Each neuron will output either “Yes ”or “No ”and give it as input to the next neuron it is connected to the right of it, which “activates ”it or allows it to give an output to other connected neurons.
Each neuron also checks for one characteristic of the image to determine if it is Mario, like if he has a Moustache, and then if he does, is the color black. If the output layer neuron receives a “Yes ”from all neurons connected to its left then it will output “Yes,”indicating the image is of Mario.
Finish the neural network by drawing logical connections from each input layer neuron to a neuron on its right. Use the picture as an indication of where the lines should be drawn. Walk through each branch of the network to make sure it makes sense (like does processing the “Moustache?”neuron and then processing the “Blue?”neuron make sense?)

Remote Control Files:
RCPi.py
Maze Solver Files:
MazeSolution.py
MazePather.py
MazeTraverser.py